For most of the remaining projects in CS 2 (including this one), you will be allowed to work in groups of two. You may discuss high-level ideas with students outside your group, but any viewing, sharing, copying, or dictating of code is forbidden. Dean’s Tutors may not read your code.
Goals and Outcomes
In this project, you will implement one data structure (called a trie) and two versions of an autocomplete algorithm (one that uses Java’s HashMap and one that uses
your Trie). Your autocomplete algorithms will then be used to be the backend of a system that complete the names of movies in a search field.
By the end of this project, you will…
- be able to run an efficient autocomplete algorithm on a variety of datasets
- understand how to implement a trie data structure and some algorithms that correspond to them
- have gained a better understanding of API design, as it relates to making projects usable with a variety of clients
Connection to Lecture
This project covers lecture08 (trees) and lecture09 (tries). You will likely find the code from these two lectures to be very useful in the later parts of this project.
Overview and Implementation Strategy
In the previous project, you wrote three implementations of the IDeque interface. This time, you will continue our mission of implementing all the data structures ourselves by
writing a trie implementation of the IDictionary interface. In addition to building a trie data structure, you will write an autocomplete algorithm which can switch between
using a backing java.util.HashMap and your very own TrieMap.
Just to be super clear: the only data structures in java.util that you are allowed to use in this project are java.util.HashMap and java.util.HashSet.
Deques Again
The first thing you should do for this project is copy over your deque implementations from project03. You may choose either partner’s implementation of each of the data structures, but,
at a minimum, you must copy over someone’s ArrayDeque and someone’s LinkedDeque. You should place them in the edu.caltech.cs2.datastructures package.
If neither partner has both IDeque’s working, e-mail Adam immediately.
HashMovieAutoCompleter Requirements
First, we will implement a movie autocompleter algorithm backed by a HashMap. Our autocomplete implementation will be case-insensitive, and will suggest a list of movie names,
given a set of words. Consider the movie database that includes the following movies:
- The Avengers
- The Avengers Age of Ultron
- Captain America
- Black Panther
- Transformers Age of Extinction
Now consider the autocomplete query "age of". We want to match on any set of consecutive words in a movie title; so, we should suggest
["The Avengers Age of Ultron", "Transformers Age of Extinction"].
However, if the query is "of age", we should not suggest anything, because none of the movies have “of” and “age” in that order.
Similarly, if our autocomplete query is "the", then we should suggest ["The Avengers", "The Avengers Age of Ultron"].
In our first AutoCompleter, HashMovieAutoCompleter, the backing data structure will be a java.util.HashMap which maps each normalized movie title
to an IDeques of “suffixes” that can be formed from that title.
For example, the above database would have the following mappings:
-
"the avengers"\(\mapsto\)["the avengers", "avengers"] -
"the avengers age of ultron"\(\mapsto\)["the avengers age of ultron", "avengers age of ultron", "age of ultron", "of ultron", "ultron"] -
"captain america"\(\mapsto\)["captain america", "america"] -
"black panther"\(\mapsto\)["black panther", "panther"] -
"transformers age of extinction"\(\mapsto\)["transformers age of extinction", "age of extinction", "of extinction", "extinction"]
public static void populateTitles()
Populates the autocompleter titles map with all suffixes for each movie title.
You will find the pre-populated field ID_MAP which maps movie titles to their IMDB ids useful. Do NOT attempt to open the data files directly; this has already
been done for you in the super class AbstractMovieAutoCompleter.
public static IDeque<String> complete(String term)
Given a search term (i.e., words separated by spaces), returns an IDeque of movie titles that are possible completions of the search term. Make sure there are
no duplicate values in the result.
The general algorithm here is to check if the search term is a prefix of any of the entries in the map. If so, it is a valid completion.
Note that “this!” does not match “this” because symbols are significant.
Imagine you want to search for “The Avengers: Age of Ultron” in the Netflix search bar. You would expect “Age of Ultron” to match, even though it isn’t the start of the title. Each suffix represents the start of a new word in the title, so by using suffixes, we allow you to start searching from any word.
However, you also don’t want to have to type in the whole search term. “Age of” should also match. This is where the prefixes come in: they are the starts of a suffix that you could be searching for. Together, this is a search for prefixes of suffixes.
In our algorithm, we are searching by words where punctuation is significant. So, “this!” has an extra exclamation point which does not match the term where there isn’t punctuation.
Task 0.
Implement the populateTitles and complete methods in HashMovieAutoCompleter.java.
Running the AutoCompleter
If all your D tests pass, you should be able to run the “Movie Autocomplete” target of the project. A browser window should automatically open with the movie finder interface.
The algorithm you just wrote backs the search for completions. We recommend trying a query like “the “ which we expect to have lots of results. You will likely notice that the interface
is noticably slow! This is all because of the data structure we chose. In the next part of the project, we will write a new data structure, called a trie, which is more suited to this
type of application.
Trie Requirements
A Trie is a dictionary which maps “strings” to some type. Unlike other trees that we’ve seen previously, each node only contains a single “letter”.
For example, here is a trie that represents the words {adam, add, app, bad, bag, bags, beds, bee, cab}:

You should be familiar with using a HashMap and a TreeMap at this point. So, we’ll start with a comparison to those.
Comparing ITrieMap to HashMap and TreeMap
It helps to compare it with dictionaries you’ve already seen: HashMap and TreeMap. Each of these types of maps takes
two generic parameters K (for the “key” type) and V (for the “value” type). It is important to understand that
Tries are NOT a general purpose data structure. There is an extra restriction on the “key” type; namely, it must be made
up of characters (it’s tempting to think of the Character type here, but really, we mean any alphabet–chars, alphabetic letters, bytes, etc.).
Example of types that Tries are good for include: String, byte[], List<E>. Examples of types
that Tries cannot be used for include int and Dictionary<E>.
In our implementation of Tries, we encode this restriction in the generic type parameters:
-
A: An “alphabet type”. For aString, it would beCharacter. For abyte[], it would beByte. -
K: A “key type”. We insist that all the “key types” extendIterable<A>which encodes exactly the restriction that there is an underlying alphabet. -
V: A “value type”. There are no special restrictions on this type.
Because the key type is iterable, there is a clean way to take apart keys (i.e., you can use a foreach loop), but we also need a way to put keys back together. To do this, we use Java’s anonymous functions.
For our purposes, what this means is that the constructor will look like this:
public ITrieMap(Function<IDeque<A>, K> collector) {
...
}
If you look at the collector function’s declaration, you will see it is listed as Function<IDeque<A>, K>. Essentially, what this means is that it has the functionality
to take an IDeque of “letters” in your alphabet and return a key that is essentially the letters concatenated together.
So if we have an IDeque called acc that contains ["h", "e", "l", "l", "o"], and
we called this.collector.apply(acc), it would return the string "hello".
You will find the collector very useful in your keys() method.
And, eventually, when we create a trie to use for autocompleting, the instantiation will look like this:
private static ITrieMap<String, IDeque<String>, IDeque<String>> titles =
new TrieMap<>((IDeque<String> s) -> s);
TrieMap
A TrieMap is an implementation of a trie where the “pointers” are made up of a HashMap. An array would work as well, but you should think about why that might not be
a good idea if the alphabet size is large (like 5 or more). Consider the following ITrieMap:
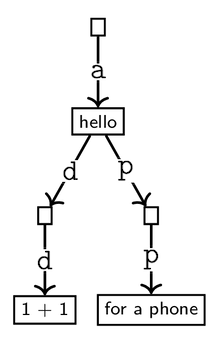
We could manually construct this as a TrieMap as follows:
this.root = new TrieNode();
this.root.pointers.put('a', new TrieNode("hello"));
this.root.pointers.get('a').pointers.put('d', new TrieNode());
this.root.pointers.get('a').pointers.get('d').pointers.put('d', new TrieNode("1 + 1"));
this.root.pointers.get('a').pointers.put('p', new TrieNode());
this.root.pointers.get('a').pointers.get('p').pointers.put('p', new TrieNode("for a phone"));
Notice that the pointers variables in each of the nodes are just standard HashMaps!
You will implement all the standard IDictionary operations. For each of these, read the comments for IDictionary for the
particulars. There are two methods (getCompletions and findPrefix) which are special for ITrieMaps and have additional information/restrictions:
-
isPrefix(K k)should returntrueiffkis a prefix of some key in the trie. For example, if “add” were a key in the trie, then:
isPrefix("”)=isPrefix("a”)=isPrefix("ad”)=isPrefix("add”)=true.
This method is arguably one of the major reasons to use aITrieMapover another implementation ofDictionary. (We saw a similar trade-off betweenHashMap(faster) andTreeMap(ordered) a few weeks ago.) Unlike in a normalIDictionary, it is possible (and in fact, easy) to implement this method. -
getCompletions(K prefix)should return anIDequefilled with the values of all descendants of the prefix. For example, in the example above:
getCompletions("")=getCompletions("a")=["hello", "1 + 1", "for a phone"]
getCompletions, keys, and values are the hardest methods to write here. You will likely want to use an “accumulator” argument
which “collects” the completions/keys/values as you recurse down the tree. The only place you will need to use the “collector” function is in keys.
Your implementations of get, put, isPrefix, and containsKey must have time complexity \(\Theta(d)\) where \(d\) is the number
of letters in the key argument of these methods. These methods work on the entire key (the whole “string” of “letters”); make sure to only remove/add/find
the exact key asked for. You will also have to implement other methods like keys and values, but the runtime of these methods may be worse.
Notably, we are not implementing the remove method right now–it’s not needed for the application; so, we’ll implement it later in the A tests.
Task 1.
Just like last time, the interface files will be very important. Carefully read the interfaces/IDictionary interface.
Task 2.
Implement the put, size, and clear methods in TrieMap.
size method counting?
The size function should return the number of key/value pairs, not the number of nodes in the trie (which might be much larger)!!!!
Task 3.
Implement the get, containsKey, and isPrefix methods.
Task 4.
Implement the values, containsValue, keys, and iterator methods. The iterator should go over the keys.
Task 5.
Implement the getCompletions method.
TrieMovieAutoCompleter Requirements
Next, we’ll implement an autocompleter that uses our trie. The specification is identical to the D part, except the main dictionary will be a trie which maps suffixes to
IDeques of titles instead of a HashMap that goes in the opposite direction. Furthermore, you will find the getCompletions method you wrote to be very useful
when implementing complete().
Task 6.
Implement the populateTitles and complete methods in TrieMovieAutoCompleter.java.
After you’ve implemented this, go to Main.java and swap out line 28. You should see a significant speed-up from the HashMap version!
TrieMap remove()
Finally, to wrap things up, go ahead and implement the remove method for your trie. remove(K k) should delete k from the trie
as well as all of the nodes that become unnecessary. One implementation of remove (called lazy deletion) would be to find
k in the map and set its value to null (since null is not a valid value in the map). You may
not implement remove as lazy deletion. Instead, you must ensure that all leaves of your trie have values.
remove MUST be written recursively to recieve any credit.
Task 7.
Implement the remove method.