Setup
Register for the lab using http://register.caltech.codes/ and clone the repository as explained in the setup instructions.
This lab is difficult. Please consider showing up to lab in person, especially if you’ve already dropped a lab! TAs will be there to support you.
Goals and Outcomes
In this lab, you will write a simple machine learning algorithm that uses a tree!
By the end of this lab, you will…
- be more familiar with basic tree algorithms
- have written a basic machine learning algorithm
Machine Learning with Decision Trees
Machine learning (ML) is all about using patterns in data to solve problems that are difficult to pin down mathematically. Typically, we build a model which aims to predict the “right” outcome given an input. This is where trees come in! One way of modeling a complex function in an intuitive manner is with a decision tree.
We will discuss how to use attributes and features to try to predict outcomes. In this lab, when we refer to an attribute, we are referring to an abstract quality or feature that can be used to categorize something. When we refer to a feature, we are referring to the realization of an attribute. For example, a Caltech student has several attributes, such as their grade and major. The specific values of these attributes are the student’s features. For example, we could consider a specific Caltech student which has “grade”=”Sophomore” and “major”=”Mechanical Engineering”.
We can use attributes and features to make a decision tree which attempts to predict an outcome - which can be the effects of an event or the answer to a question. For example, imagine all Mechanical and Electrical Engineering Caltech students had to take a thermodynamics exam. Since MechEs learn thermodynamics and EEs don’t, the raw data would show a greater percentage of MechEs passed the exam compared to EEs, and that less frosh MechE majors passed compared to non-frosh. Therefore, a decision tree made from this dataset might look like this:
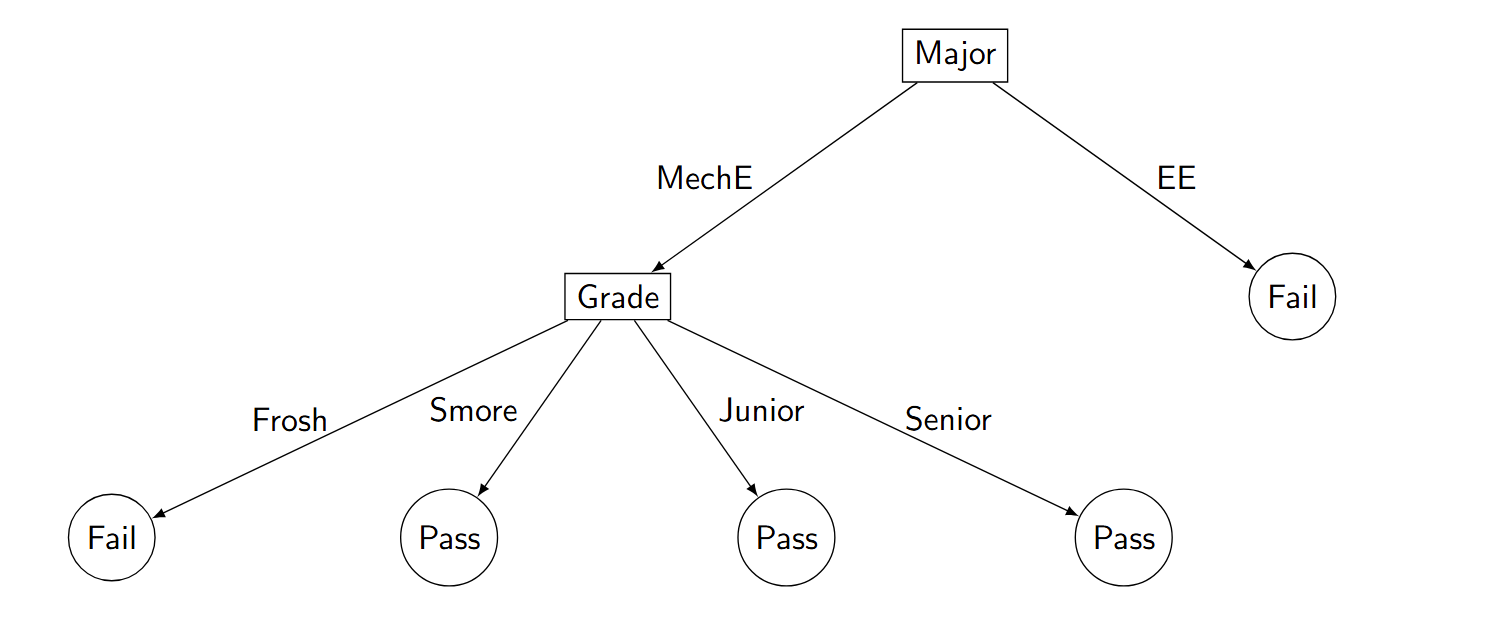
Now, let’s imagine we have the features of a new student who missed the exam. For example, “grade”=”Junior” and “major”=”Mechanical Engineering”. Using these features, we can navigate down our decision tree and return a predicted outcome:
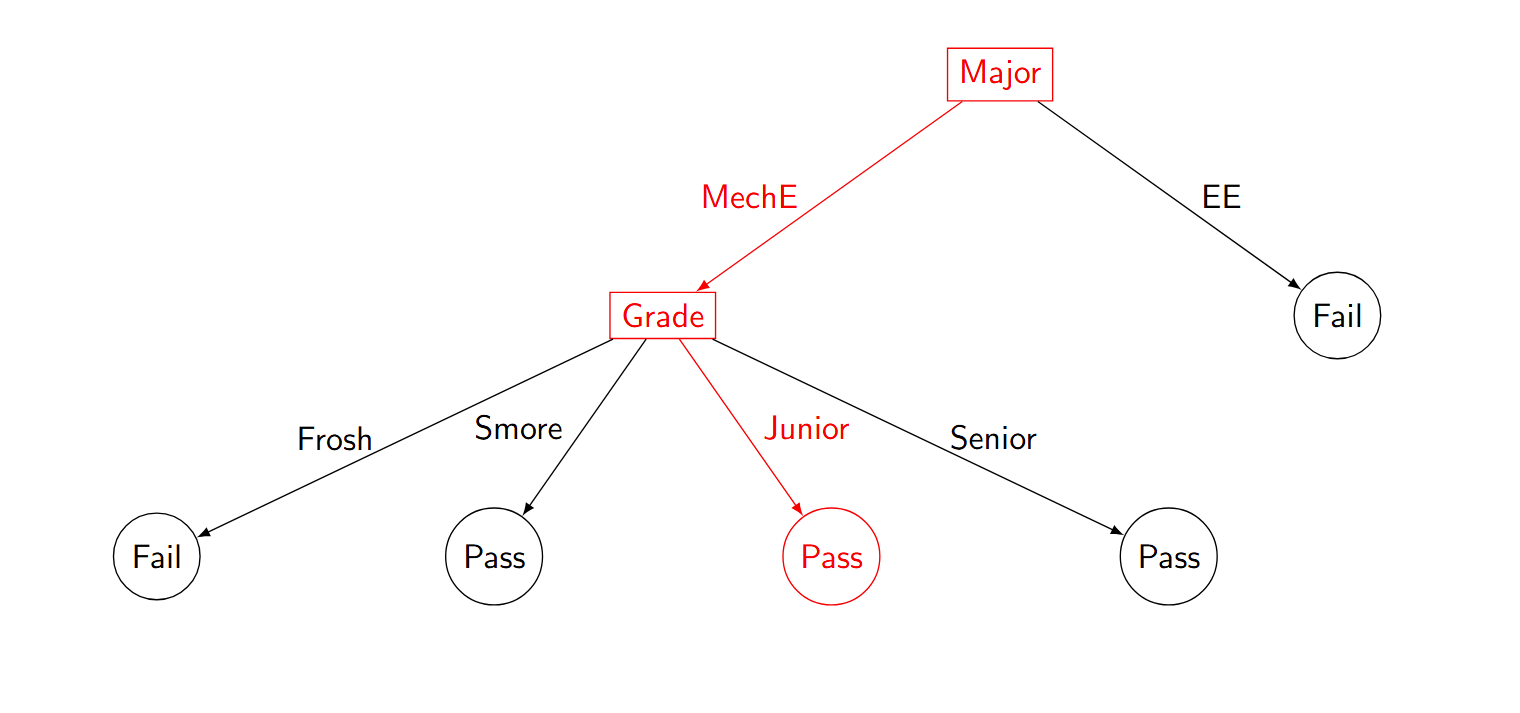
ID3 Algorithm
So, how do we actually make a decision tree from a dataset? In this lab, we will use the Iterative Dichotomizer 3 (ID3) algorithm to predict whether a passenger survived the Titanic disaster. We will look at several (problematic) attributes of the passengers (e.g., “age”) and try to use each passenger’s features (realizations of each attribute, e.g. “age”=”old” or “age”=”young”) to predict their outcome (e.g., dead or alive).
To do this, we will build a tree where each non-leaf node represents an attribute and each leaf node represents an outcome. The features are represented as edges and determine which path down the tree a given passenger (datapoint) takes, and ultimately their predicted outcome.
For example, ID3 might output a tree that looks like the following:
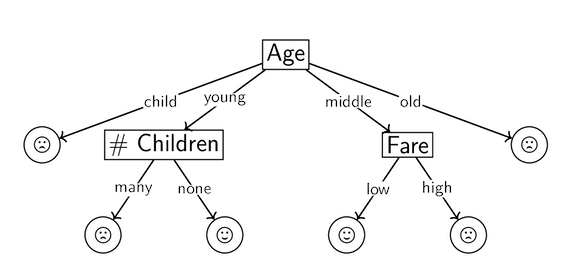
We need some metric to decide how to build our decision tree from the available attributes–which attributes do we want to split on earlier, and which are we okay leaving for later?
Entropy is a fitting metric for such a decision tree: it is the expected value of information content when measuring the outcome of an event. By minimizing entropy as we build the tree from the root, we can narrow down from the more general attributes to the more specific ones and thus minimize uncertainty. We used a similar metric for predicting “englishness” in project01, and like last time, you won’t have to compute entropy yourself.
For this lab, you will need to use methods from the Dataset class. To do this PLEASE take a look at the Dataset class. It will help you a lot!
The pseudocode for constructing the ID3 decision tree is as follows:
id3helper(data, attributes):
- If all the remaining data points have the same outcome:
- Return an outcome node with this outcome
- If there are no remaining attributes:
- Return an outcome node with the most common outcome
- Find the lowest entropy attribute, \(a\).
- For each feature, \(f\), of \(a\):
- Find all the data points that have the feature \(f\).
- If there are none:
- Guess! Make an outcome child with the most common outcome.
- Otherwise:
- Use the data! Recursively make a child out of the remaining data points, using all attributes except for \(a\).
- Return the attribute node with the children generated above.
Task 0.
Write the id3helper method in DecisionTree.java according to the specification above.
Task 1.
Once the decision tree is built, it’s time to predict! Given a data point, we traverse the decision tree until we hit a leaf node.
Implement this tree traversal recursively or iteratively as the predict method in DecisionTree.java.
Hints:
- If you can’t get
root.children, you should rememberrootis aDecisionTreeNode, so it doesn’t have achildrenfield by default. You should castrootto anAttributeNode, which implementsDecisionTreeNode, to access its children and attributes. - You can get the
outcomeof a node only if it is anOutcomeNode. Note that you can cast aDecisionTreeNodeto anOutcomeNode, but you can’t cast anAttributeNodeto anOutcomeNode.
Checking the Results on gitlab
Task 2. Check to make sure you are passing all the tests on gitlab.
Ethics and AI
Several of the attributes (e.g., age, sex at birth, wealth) of our model are problematic in terms of equity. For example, if someone used our model during another Titanic-like disaster to determine who got to board the lifeboats first, it would produce biased results. Ponder for a while about what responsibility we have as computer scientists to the communities using our products, and how can we correct for biases when training our models.